Part 3: Bot technical details
Beep boop.

This is part 3 of a 5 part series; the index with links to other sections is here.
I’ll skip over all the earlier incarnations and just talk about the most relevant and advanced version.
The user base
Although in the earlier phases the bot mostly had technical users, as time went on we had more non-technical users. People who didn’t know what a VM, a bash shell, python, etc were.
Literally everything became optimized to prevent me having to spend a lot of time troubleshooting for these people. There were a lot of days early on where I spent more time helping people set up than actually doing any development work.
Onboarding
All the code was checked into a GitHub private repo. When users onboarded, they got access to the repo, and pointed to a README file that contained setup instructions.
Onboarding 20+ people (some with several wallets each) was quite a challenge, and improved quite a bit over time as I discovered ways to improve things.
The final setup looked like this:
Users signed up for Google Cloud, possibly getting free credits
Created a project and gave me the project ID for whitelisting
They downloaded and executed a Google Deployment Manager definition that spun up a server with the right configuration in the right region using a snapshotted VM state with all the dependencies installed, and a GitHub ssh key for the private repo already installed.
They log into the VM via SSH, run another command to download a set of bash scripts.
They run one script to populate their private key.
They run another script to configure their web password.
They log into a web UI that allows them to configure the bot.
They run a final script to turn on the bot.
Updating
The bot went through an extremely high paced development lifecycle. I checked in updates several times a day, sometimes critical required updates, sometimes just performance improvements, sometimes new features. Basically anyone who didn’t update their bot at least once a day would make less money.
Once I realized that no one gave a shit about reviewing the code or things being safe from me having power over their wallets, I optimized everything for ease of install and update. The ‘restart’ script:
Updated all bot requirements
Pulled the latest code
Killed the existing bot
Started new bot processes
Management
Originally users had to edit their bot configurations in the VM, but VirtualQuery was nice enough to design and build a web-based config UI that dramatically reduced the amount of shell-time required to just setting up your private key and password.

Alerting
All bot actions got mirrored to Discord for monitoring.
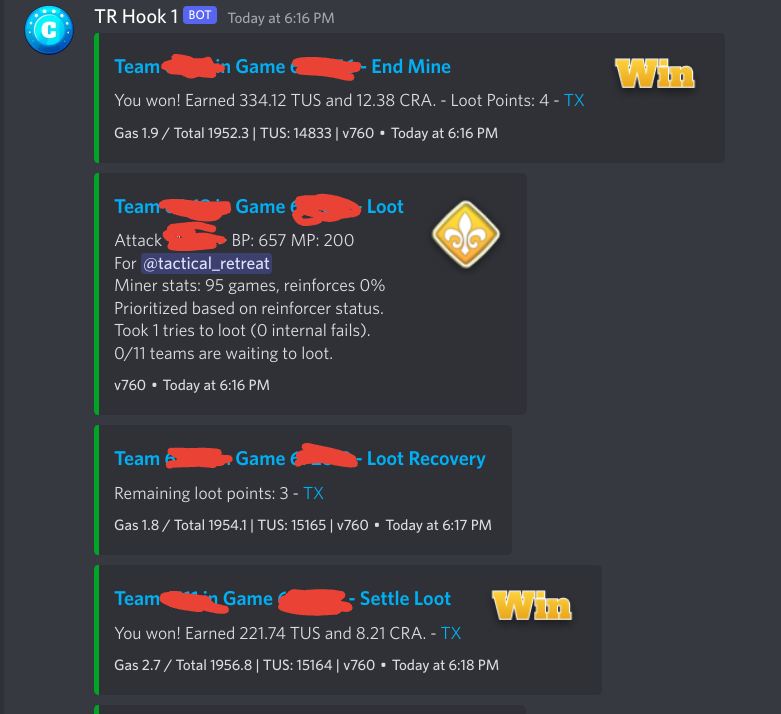
For the occasional ‘why is my bot busted’ scenario I provided a script that would bundle all the log files up, upload them to Google Cloud Storage, and share them with me for review. But people got pretty good at looking at their logs and figuring out things themselves.
Since the bots would check in for updated configurations every few minutes, I also added a monitor that would fire if a bot hadn’t checked in for a while.

Looting health
Besides the live ‘master alert channel’ that everyone would webhook their loots to (basically 4-8 loots per minute means things are working), I eventually created a dashboard that showed how well we were doing at picking up loots.

Distinction above is between failures are related to our server / captcha solving vs how many attack requests fail after the captcha was solved successfully.
Payments
Typical dev, I spent most of my time on the tech and not enough time on making sure people paid. It took ages for me to get a working accounting system; for a while I was asking people to just guestimate what they owed and send it.
And I literally just finished creating a report that automatically confirmed if people paid, only two months later. I would just spot check a few times a week.
VirtualQuery was nice enough to build this web-based report for people to use to check what they owed, once I had accounting available. Complete with sarcastic quotes lifted from the Crabada Discord.
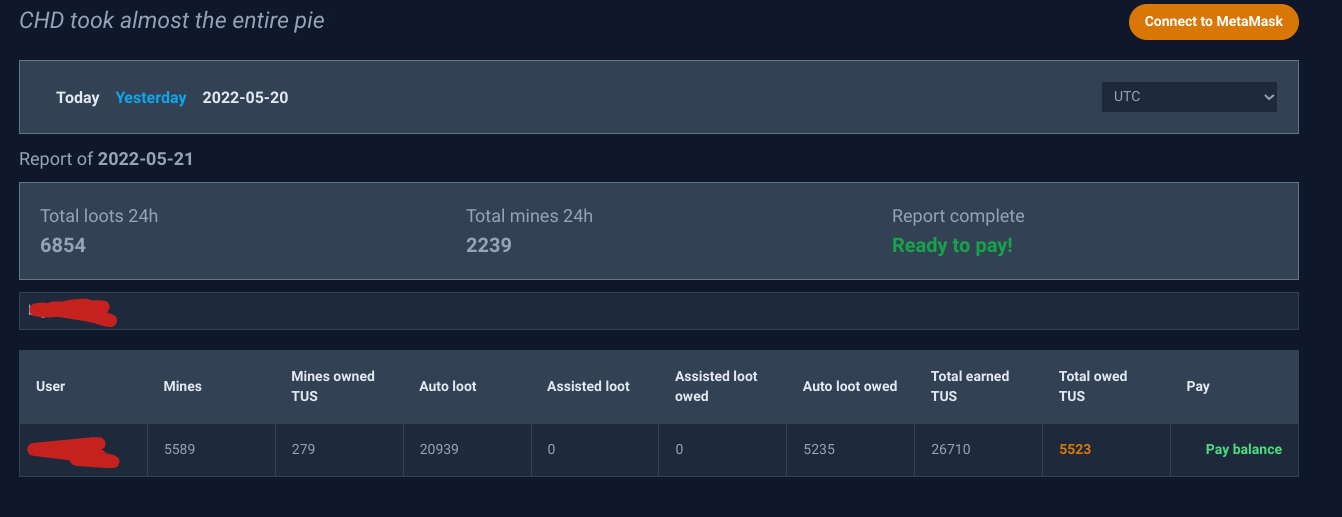
As people paid, a webhook posted their payments to a public channel in the discord.
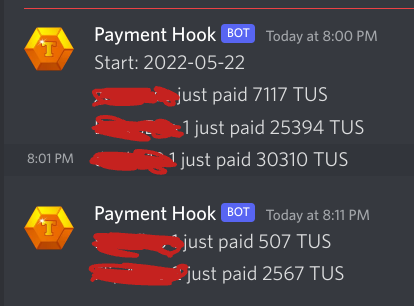
A few times I had to poke people to pay up, and some people just randomly skipped paying some days and I didn’t have the energy or interest in following up, but I think the overall compliance rate was pretty good.
The Bot VM
Every wallet had its own VM (not a hard requirement, just easier to manage this way). I recommended people loot with no more than 15 teams per VM, but people had success with up to 30 teams.
The VM communicated with the config server to fetch details about what it should do, to report accounting details, and to figure out if it should update and restart.
There were two main processes on the VM, the manager and the looter.
The ‘Manager’
A process called run_manager.py handled most operations. Basically just a polling loop that executed every 30s, fetched the state of all teams, and figured out if anything needed to be done (start a mine/send the TX to start a loot, reinforce a mine/loot, end a mine/loot) and executed it.
I had a lot of trouble with the Crabada Idle API being slow or broken, so I switched almost all functions to use the smart contract. Really the only thing I never got rid of was the tavern API.
This had all the tricks you would expect; picking the best reinforcement based on MR (under a TUS cap), trying to snipe legendaries that were underpriced, dynamic gas limits for normal / time-limited actions, etc.
The ‘Looter’
A separate process called run_looter.py handled looting. Originally this was because looting was a very latency sensitive task, later because I had several different iterations of looting that people could try, and ultimately because I was too lazy to combine it with the manager nicely.
Here is what the architecture looks like for looting:

If a team was configured to loot and had loot points:
Every minute the looter would fetch status of all looting teams, and identify the teams that were ready to loot.
If any team was ready to loot, we would look for a mine that we could loot.
The bot swapped between ‘Priority’ mode where it would only target mines that were unlikely to reinforce, and ‘Normal’ mode where it would attempt to loot any mine that any team could loot.
Users could configure duration of priority mode and the ‘acceptable’ reinforcement % for the victim. I controlled the required history for a miner to be eligible for targeting in this mode.
Once we had paired a target with a looter, we formulated a request and sent it to one of a range of proxy processes.
The proxy would submit a request to the captcha solving service telling it to fetch a captcha using itself as the GeeTest endpoint.
The proxy server would forward the request to the Crabada GeeTest proxy endpoint.
The Crabada GeeTest proxy forwards the request to the GeeTest API
After the captcha is solved correctly, the proxy server formulates an attack request and sends it to the Crabada API
The looter process is done; on the next cycle, the manager process will notice that a loot is waiting to be recovered, and send the appropriate TX to do so.
For technical and performance reasons I used a range of proxy servers, but each loot only required the use of one proxy at a time.
Background jobs
It’s not that interesting but I had a bunch of jobs that ran on a cron on my config server that would do things like look for newly hatched crabs, check team compositions, record miner/looter history, etc. The bots all used the data that this centralized job cached.
It was really annoying when they started adding ridiculous rate limits to the API, but I had a bunch of proxy servers lying around, so not that big of a deal.
Building my own Captcha Solver
It is of course, possible to build your own captcha solver. For me this was relatively low priority; I was spending pennies per loot on this external service, and the time required to replace it was better spent on one of a million other things in my todo list.
But eventually I did get around to doing this. I think anyone who is interested in building a loot bot eventually stumbles across this one article from a few years ago about cracking the GeeTest captcha. The article itself notes that the success rate isn’t that high, and anyone trying to use the associated code will soon confirm that.
But I happen to have a bunch of computer vision experience from a previous project, so I was game to try and beat his results. Note that also from a previous project I had learned that machine learning is a more accurate/easier way to do this, but it is more tedious and less fun. So I stupidly tried to do it using OpenCV first.
And I did a pretty good job. I had about a 70% success rate… and it only wasted 3 days of my life. I used a bunch of complicated and annoying thresholding / edge detection / contouring tricks and built a visualizer for the results.

Upper left is original, upper right is with some tricks applied to try and remove regions that are definitely not the stamps. The middle part is the icons, the transformed icons, the icons we found in the picture, and the ‘best’ thresholded value that was used to match against them. Bottom is the original image with my button presses.
Not bad! Not great, but not bad. Better success rate than the captcha solving service.
But I had some free time one day, and I decided to prep a data set that I could use to train Google AutoML. After about three hours of boxing stupid sample images, and two hours of training the model, I had my results.

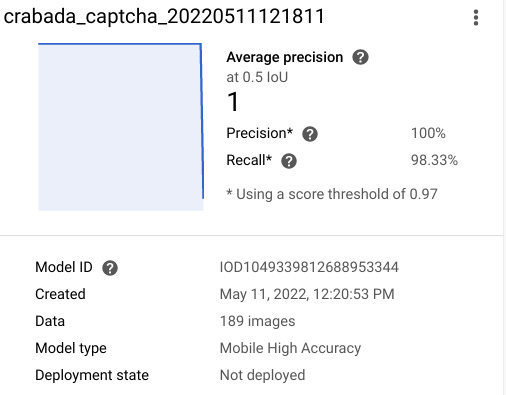
Unfortunately, building the solver and automating it using Selenium turned out to be easy on my desktop, harder on my server. Since things needed to be snappy, I did a lot of work to pool ChromeDriver instances and keep them primed. Theoretically this is easy to do, but in practice ChromeDriver tends to freak out, stop responding, leak resources, etc.
I saw a noticeable dip in performance for loots that went through the proxy I tested it on, so I reluctantly rolled this back. I prepaid for quite a few captcha solves from the service, and those will likely last until it becomes unprofitable to bot. I’m not that interested in spending more time on this.
Up Next: Part 4: Closing thoughts